from utils import llama, code_llama
temp_min = [42, 52, 47, 47, 53, 48, 47, 53, 55, 56, 57, 50, 48, 45]
temp_max = [55, 57, 59, 59, 58, 62, 65, 65, 64, 63, 60, 60, 62, 62]
prompt = f"""
Below is the 14 day temperature forecast in fahrenheit degree:
14-day low temperatures: {temp_min}
14-day high temperatures: {temp_max}
Which day has the lowest temperature?
"""
#Using the base 7B model
response = llama(prompt)
print(response)Python Code
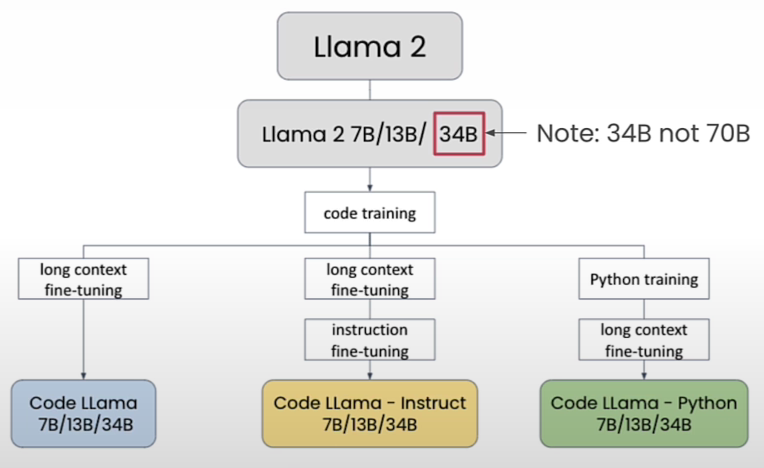
Code Llama
Here is a typical list of Code Llama that would be provided by your Cloud Service Provider if you are using one (this one is provided by together.ai)
togethercomputer/CodeLlama-7btogethercomputer/CodeLlama-13btogethercomputer/CodeLlama-34btogethercomputer/CodeLlama-7b-Pythontogethercomputer/CodeLlama-13b-Pythontogethercomputer/CodeLlama-34b-Pythontogethercomputer/CodeLlama-7b-Instructtogethercomputer/CodeLlama-13b-Instructtogethercomputer/CodeLlama-34b-Instruct
Utils.py is provided again at the end of the page,
Solve Math Problem
Let’s ask it to write code to solve the problem
Code for Function
prompt_2 = f"""
Write Python code that can calculate
the minimum of the list temp_min
and the maximum of the list temp_max
"""
response_2 = code_llama(prompt_2)
print(response_2)
def get_min_max(temp_min, temp_max):
return min(temp_min), max(temp_max)Use function on lists above
temp_min = [42, 52, 47, 47, 53, 48, 47, 53, 55, 56, 57, 50, 48, 45]
temp_max = [55, 57, 59, 59, 58, 62, 65, 65, 64, 63, 60, 60, 62, 62]
results = get_min_max(temp_min, temp_max)
print(results)Code for Fibonacci Calculation
Write a prompt that asks the model to write code that will calculate the fibonacci number
prompt = """
Provide a function that calculates the n-th fibonacci number.
"""
response = code_llama(prompt, verbose=True)
print(response)
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)Code Filling
Use Code Llama to fill in partially completed code
- Notice the [INST] ..[/INST] tags inserted into the prompt by the function
prompt = """
def star_rating(n):
'''
This function returns a rating given the number n,
where n is an integers from 1 to 5.
'''
if n == 1:
rating="poor"
<FILL>
elif n == 5:
rating="excellent"
return rating
"""
response = code_llama(prompt,
verbose=True)
print(response)Improve Code Efficiency
Make Code more Efficient
- Let’s ask the model to critic its initial code that was generated
code = """
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
"""
prompt_1 = f"""
For the following code: {code}
Is this implementation efficient?
Please explain.
"""
response_1 = code_llama(prompt_1, verbose=True)
print(response_1)
# ....A more efficient implementation of the Fibonacci sequence would be to use a loop instead of recursion, like this:
def fibonacci(n):
a, b = 0,1
for i in range(n):
a, b = b, a+b
return a
#This implementation has a time complexity of 0(n), which means that the time it takes to compute the nth Fibonacci number grows linearly with the size of the inputCode to Compare Functions
- Let’s run both functions and monitor the time it takes for each
- Let’s ask the model to provide code to compare the two
prompt = f"""
Provide sample code that calculates the runtime of a Python function call
"""
response = code_llama(prompt, verbose = True)
print(response)
Prompt:
[INST]
Provide sample code that calculates the runtime of a Python function call
[/INST]
model: togethercomputer/CodeLlama-7b-Instruct
import time
def my_function():
# do something
pass
start_time = time.time()
my_function()
end_time = time.time()
print("Runtime:", end_time - start_time)Run Time Test1
- Let’s first run the test on the first function
- Remember here is the first function
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)import time
n=40
start_time = time.time()
fibonacci(n)
end_time = time.time()
print(f"Recursive fibonacci({n}) ")
print(f"Runtime in seconds:{end_time - start_time}")
Recursive fibonacci(40)
Runtime in seconds: 19.5236082Run Time Test2
- Let’s run the so-called more efficient non-recursive function
- Remember the function is listed next
def fibonacci_fast(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aimport time
n=40
start_time = time.time()
fibonacci_fast(n)
end_time = time.time()
print(f"Recursive fibonacci_fast({n}) ")
print(f"Runtime in seconds:{end_time - start_time}")
Recursive fibonacci_fast(40)
Runtime in seconds: 9.89437e-05Considerably faster as in a fraction of a second
Input Larger Text
Remember we had limitations when we used the non code Llama, but we can find a way around it by using Code-Llama
- Code Llama models can handle much larger input text than the Llama Chat models - more than 20,000 characters.
- The size of the input text is known as the context window
- Let’s try to run the same example here it was using the Llama 2 7B Chat model, and we received an error message
with open("TheVelveteenRabbit.txt", 'r', encoding='utf-8') as file:
text = file.read()
prompt=f"""
Give me a summary of the following text in 50 words:\n\n
{text}
"""
# Ask the 7B model to respond
response = llama(prompt)
print(response)Run it in Code-Llama
- We receive an output
from utils import llama
with open("TheVelveteenRabbit.txt", 'r', encoding='utf-8') as file:
text = file.read()
prompt=f"""
Give me a summary of the following text in 50 words:\n\n
{text}
"""
response = code_llama(prompt)
print(response)Utils.py
import os
from dotenv import load_dotenv
import os
from dotenv import load_dotenv, find_dotenv
import warnings
import requests
import json
import time
# Initailize global variables
_ = load_dotenv(find_dotenv())
# warnings.filterwarnings('ignore')
url = f"{os.getenv('DLAI_TOGETHER_API_BASE', 'https://api.together.xyz')}/inference"
headers = {
"Authorization": f"Bearer {os.getenv('TOGETHER_API_KEY')}",
"Content-Type": "application/json"
}
# which allow for the largest number of
# tokens for the input prompt:
# I think max_tokens set the maximum that can be output
# but the sum of tokens from input prompt and response
# can not exceed 4097.
def code_llama(prompt,
model="togethercomputer/CodeLlama-7b-Instruct",
temperature=0.0,
max_tokens=1024,
verbose=False,
url=url,
headers=headers,
base=2,
max_tries=3):
if model.endswith("Instruct"):
prompt = f"[INST]{prompt}[/INST]"
if verbose:
print(f"Prompt:\n{prompt}\n")
print(f"model: {model}")
data = {
"model": model,
"prompt": prompt,
"temperature": temperature,
"max_tokens": max_tokens
}
# Allow multiple attempts to call the API incase of downtime.
# Return provided response to user after 3 failed attempts.
wait_seconds = [base**i for i in range(max_tries)]
for num_tries in range(max_tries):
try:
response = requests.post(url, headers=headers, json=data)
return response.json()['output']['choices'][0]['text']
except Exception as e:
if response.status_code != 500:
return response.json()
print(f"error message: {e}")
print(f"response object: {response}")
print(f"num_tries {num_tries}")
print(f"Waiting {wait_seconds[num_tries]} seconds before automatically trying again.")
time.sleep(wait_seconds[num_tries])
print(f"Tried {max_tries} times to make API call to get a valid response object")
print("Returning provided response")
return response
# 20 is the minum new tokens,
# which allow for the largest number of
# tokens for the input prompt: 4097 - 20 = 4077
# But max_tokens limits the number of output tokens
# sum of input prompt tokens + max_tokens (response)
# can't exceed 4097.
def llama(prompt,
add_inst=True,
model="togethercomputer/llama-2-7b-chat",
temperature=0.0,
max_tokens=1024,
verbose=False,
url=url,
headers=headers,
base=2, # number of seconds to wait
max_tries=3):
if add_inst:
prompt = f"[INST]{prompt}[/INST]"
if verbose:
print(f"Prompt:\n{prompt}\n")
print(f"model: {model}")
data = {
"model": model,
"prompt": prompt,
"temperature": temperature,
"max_tokens": max_tokens
}
# Allow multiple attempts to call the API incase of downtime.
# Return provided response to user after 3 failed attempts.
wait_seconds = [base**i for i in range(max_tries)]
for num_tries in range(max_tries):
try:
response = requests.post(url, headers=headers, json=data)
return response.json()['output']['choices'][0]['text']
except Exception as e:
if response.status_code != 500:
return response.json()
print(f"error message: {e}")
print(f"response object: {response}")
print(f"num_tries {num_tries}")
print(f"Waiting {wait_seconds[num_tries]} seconds before automatically trying again.")
time.sleep(wait_seconds[num_tries])
print(f"Tried {max_tries} times to make API call to get a valid response object")
print("Returning provided response")
return response
def llama_chat(prompts,
responses,
model="togethercomputer/llama-2-7b-chat",
temperature=0.0,
max_tokens=1024,
verbose=False,
url=url,
headers=headers,
base=2,
max_tries=3
):
prompt = get_prompt_chat(prompts,responses)
# Allow multiple attempts to call the API incase of downtime.
# Return provided response to user after 3 failed attempts.
wait_seconds = [base**i for i in range(max_tries)]
for num_tries in range(max_tries):
try:
response = llama(prompt=prompt,
add_inst=False,
model=model,
temperature=temperature,
max_tokens=max_tokens,
verbose=verbose,
url=url,
headers=headers
)
return response
except Exception as e:
if response.status_code != 500:
return response.json()
print(f"error message: {e}")
print(f"response object: {response}")
print(f"num_tries {num_tries}")
print(f"Waiting {wait_seconds[num_tries]} seconds before automatically trying again.")
time.sleep(wait_seconds[num_tries])
print(f"Tried {max_tries} times to make API call to get a valid response object")
print("Returning provided response")
return response
def get_prompt_chat(prompts, responses):
prompt_chat = f"<s>[INST] {prompts[0]} [/INST]"
for n, response in enumerate(responses):
prompt = prompts[n + 1]
prompt_chat += f"\n{response}\n </s><s>[INST] \n{ prompt }\n [/INST]"
return prompt_chat